Reference: https://github.com/gilbutITbook/080289
GitHub - gilbutITbook/080289
Contribute to gilbutITbook/080289 development by creating an account on GitHub.
github.com
하이퍼 파라미터 이용 성능최적화 방법: 배치 정규화, 드롭아웃, 조기 종료
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
배치 정규화
유사 용어들.
정규화
- 데이터 범위를 사용자가 원하는 범위로 제한 하는 것.
ex. 이미지 데이터는 픽셀 정보로 0~255 값을 갖는데 이를 255로 나누면 0~1.0의 값을 갖게 됨.
- 각 특성 범위(스케일(scale))를 조정한다는 의미로 특성 스케일링(feature scaling)이라고도 함.
규제화
- 모델 복잡도를 줄이기 위해 제약을 두는 방법.
- 데이터가 네트워크에 들어가기 전 필터를 적용하는 것과 비슷.
- 규제를 이용해 모델 복잡도를 줄이는 방법: 드롭아웃, 조기 종료.
표준화
- 기존 데이터를 평균은 0, 표준편차는 1인 형태의 데이터로 만드는 방법.
- 표준화 스칼라 , z-스코어 정규화라고도 함.
- 평균을 기준으로 얼마나 떨어져 있는지 살펴볼 때 사용
배치 정규화
- 2015년 “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”
- 기울기 소멸(gradient vanishing)이나 기울기 폭발(gradient exploding) 같은 문제를 해결하고, 데이터 분포가 안정되어 학습 속도를 높이는 방법.
- 손실 함수로 렐루(ReLU)를 사용하거나 초깃값 튜닝, 학습률(learning rate) 등을 조정
- 기울기 소멸과 폭발의 원인은, 네트워크의 각 층마다 활성화 함수가 적용되면서 입력 값들의 분포가 계속 바뀌는
내부 공변량 변화 때문.
- 분산된 분포를 정규분포로 만들기 위해 미니 정규화 적용.
(미니 배치 평균 - 미니 배치 분산 및 표준편차 계산 - 정규화 수행 - 스케일 조정:데이터분포 조정 순)
- 이러한 방식은 배치 크기가 작을 때는 정규화 값이 기존 값과 다른 방향으로 분련될 수 있고
- RNN의 경우 네트워크 별로 미니 정규화를 적용해야 하므로 비효율적.
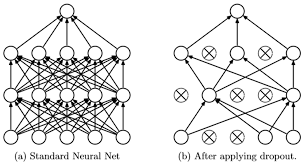
드롭아웃
- 과적합: 훈련 데이터셋을 과하게 학습하는 것.
- 훈련 데이터셋은 실제 데이터셋의 부분 집합이므로 훈련 데이터셋에 대해서는 오류가 감소하지만, 테스트 데이터셋에 대해서는 오류가 증가함 = 과적합
- 드롭아웃(dropout)은 훈련할 때 일정 비율의 뉴런만 사용하고, 나머지 뉴런에 해당하는 가중치는 업데이트하지 않는 방법
- 매 단계마다 사용하지 않는 뉴런을 바꾸어 가며 훈련, 은닉층에 배치된 노드 중 일부를 임의로 끄면서 학습.
- 꺼진 노드는 신호를 전달하지 않으므로 지나친 학습을 방지하는 효과
- 테스트 데이터로 평가할 때는 노드들을 모두 사용하여 출력하되 노드 삭제 비율(드롭아웃 비율)을 곱해서 성능을 평가합니다.
- 훈련 시간이 길어진다는 단점 but 성능 향상.
조기 종료
- 조기 종료(early stopping)는 뉴럴 네트워크가 과적합을 회피하는 규제 기법
- 훈련 데이터와 별도로 검증 데이터를 준비하고, 매 에포크마다 검증 데이터에 대한 오차(validation loss)를 측정하여 모델의 종료 시점을 제어.
- 과적합이 발생하기 전까지 학습에 대한 오차(training loss)와 검증에 대한 오차 모두 감소하지만, 과적합이 발생하면 훈련 데이터셋에 대한 오차는 감소하는 반면 검증 데이터셋에 대한 오차는 증가함. 따라서 검증 데이터셋에 대한 오차가 증가하는 시점에서 학습을 멈추도록 조정
'AI > Theory_Private' 카테고리의 다른 글
| 전처리 (0) | 2023.06.10 |
|---|---|
| GRU 게이트 순환 신경망 (0) | 2023.05.27 |
| Time Series Regression 1 (0) | 2023.04.20 |
| 시계열 분석 (0) | 2023.04.15 |
| Attention (from seq2seq) Review (0) | 2023.04.11 |


